The first volume of the PPI Journal included a tutorial article on Little’s Law, explaining the fundamental relationship between throughput, cycle time and work-in-process (WIP) for all production systems, including those that are contained within capital projects. For those new to Operations Sciences, a more naïve interpretation of Little’s Law leads novices to infer that one need only increase WIP arbitrarily high to increase throughput to whatever target level is desired. While Little’s Law is generally true under very broad assumptions, it cannot always be treated as if any pair of variables selected from throughput, WIP and cycle time can be independently altered to set the third variable to a desired target. Real production systems always have other physical constraints that place upper limits on throughput and lower limits on cycle time.
Through some simple examples, we explain how physical constraints manifest themselves in limiting the range of feasible values that throughput, cycle time and WIP can achieve. The discussion leads to the important concept of Critical WIP, which is the minimum WIP level necessary to achieve the maximum throughput in a production system where there is no variability. We then provide a qualitative discussion about how variability affects system performance and affects the optimum level of WIP necessary to achieve desirable throughput and cycle time performance. Finally, we conclude with a discussion of how adding capacity at non-bottlenecks can improve performance when there is significant variability.
Keywords: Little’s Law; Optimal Level of WIP; Critical WIP
The Project Production Institute regularly conducts seminars to introduce and explain concepts underlying Project Production Management (PPM), including the fundamental principles of Operations Science. It is eye-opening to see the variation in understanding and intuition to predict the behavior of a production system, which frequently results in incorrect predictions.
Over the years, we have conducted a seminar exercise where participants are given blank graphs (below in Figure 1) and asked to draw the relationship between work-in-process (WIP) and throughput in one, and the relationship between work-in-process (WIP) and cycle time in the other.
Figure 1: What are the relationships between throughput, cycle time and WIP?
Surprisingly, we receive all sorts of answers, some showing relationships that are exactly the opposite of each other. The variation in understanding and intuition may explain why people are often working on the wrong problems or trying to implement the wrong solutions in attempts to solve the right problems.
Therefore, it is critical to fully understand these relationships, which leads us to the purpose of this tutorial.
Let’s examine the following relationships, starting with Little’s Law [1] and using a simple example.
The original form of Little’s Law is WIP = TH x CT. Algebraically, this can then be written as TH = WIP / CT and CT = WIP / TH. Therefore, in Institute seminars, participants sometimes misunderstand that Little’s Law implies that the throughput can be made arbitrarily large, simply by increasing the WIP.
Indeed, this is sometimes used as a justification for the common project management practice of accumulating large amounts of inventory in a project because “having all the materials available ensures optimum project execution with the minimum schedule.” There are plenty of surveys of project performance that demonstrate that such a belief is not supported by actual project outcomes achieved. Little’s Law does indeed constrain the three variables: TH, WIP and CT. But one relation with three variables does not allow us to predict the other two when knowing one of the three. We need another relationship.
A simple example (adapted from Factory Physics’ Penny Fab Example [1], p233), such as shown in Figure 2, demonstrates the relationship.
 Figure 2: Example Production System with four distinct operations
Figure 2: Example Production System with four distinct operations
For the sake of concreteness, let’s suppose this is a description of the steps involved to drill a well and tie it up to a pipeline infrastructure to produce oil and/or gas. The sequence of numbered steps, at a high level, are:
For the sake of simplicity, let’s assume that each operation has one team, crew or machine and therefore, cannot handle any more than one well at a time. For example, the team working on securing permits can only work on the permits for one well and cannot start on the permits for the next well until the permits for the preceding well have been secured. Similarly, the drilling rig can only be drilling one well at a time and cannot start drilling the next well until drilling the preceding well is completed. And the situation is the same for the crew doing the well completion and tying up the producing well to the pipeline: each team can only work on one well at a time. In other words, we are specifying the amount of the capacity contributors (labor, equipment and space) in each step to be one.
We’ll also assume, for the sake of simplicity, that there is absolutely no variability in the system. Each step takes a predictably constant processing time and there are no delays anywhere in the system. Let’s also suppose each operation takes 10 days, meaning each individual step has its own cycle time of 10 days. Then, assuming there is no waiting time in between any of the steps, the total cycle time is 40 days, which represents the total time a well resides within the entire process from start (securing the permits) to finish (producing well is connected to pipeline). Therefore, each step has its own individual throughput of processing one well every 10 days, or 0.1 wells/day. And if a well is handed off from one step to the succeeding step without any delay, then it’s easy to see that the throughput of the entire system is also, at most, 0.1 wells/day, or 1 well every 10 days. After an initial startup, meaning the very first well will take 40 days to appear, the subsequent wells will come online at the rate of 1 every 10 days. The throughput of the entire production system is therefore 0.1 wells/day.
It now follows from Little’s Law that the total WIP in the system is TH*CT = 0.1 * 40 = 4 wells. It is not surprising, as it’s quite clear from our starting assumptions, that there is a well being worked on in each of the four steps in the well production system in Figure 2.
So, is it possible to increase the overall throughput by increasing WIP? Any production system is simply the aggregation of individual operations, arranged sequentially in a line or routing, or perhaps a parallel arrangement of multiple lines, or perhaps an even more complex network. However, looking at any of the individual steps involved shows the reader why this cannot be the case.
For any individual operation which is performed by some form of labor, equipment and space, it is easy to see that there will generally be an upper limit on the throughput of that individual step (capacity) and a lower limit on its individual cycle time. For instance, in our simple example, one might conceivably get the team in Step 1 to be simultaneously securing the permits of more than one well at a time. One also might be able to improve the actual process of permits to reduce the overall time needed to get a permit. But one will never be able to get the cycle time to zero, nor will one be able to get the number of wells being permitted to be arbitrarily high. Similarly, perhaps a more advanced drilling rig can drill up to 4 or 5 wells at a time, but there will always be a finite upper limit to the number of wells that can be drilled simultaneously, i.e. an upper bound on the throughput of a drilling rig. And it is also true there is a lower limit on the cycle time for drilling, and it won’t come arbitrarily close to zero.
Within the overall production system there will always be an individual step or steps limiting the overall throughput – the bottleneck, constraining the overall system performance. Increasing WIP arbitrarily will not overcome the limiting effects of the bottleneck.
Let’s examine our example production system as it starts up, to generate the graphs in Figure 1 for our example production system in Figure 2. The unit of WIP in this case is a “well,” which has to undergo four steps (permitting, drilling, completion and tying up) to pass through a production system. As the wells are being put into the production system at the beginning, it is easy to see that the values for WIP, TH and CT evolve, as shown in Table 1:
| WIP (Wells) | TH (Wells/Day) | CT (Days) |
| 1 | 0.025 | 40 |
| 2 | 0.050 | 40 |
| 3 | 0.075 | 40 |
| 4 | 0.1 | 40 |
| 5 | 0.1 | 50 |
| 6 | 0.1 | 60 |
| … | 0.1 | … |
| 40 | 0.1 | 400 |
Table 1: Values of throughpu. WIP and cycle time for the system in Figure 2
So, we can now produce the graphs in Figure 1 from the tabulated data in Table 1 to produce Figure 3, where the left vertical axis is used for TH and the right vertical axis is used for CT.
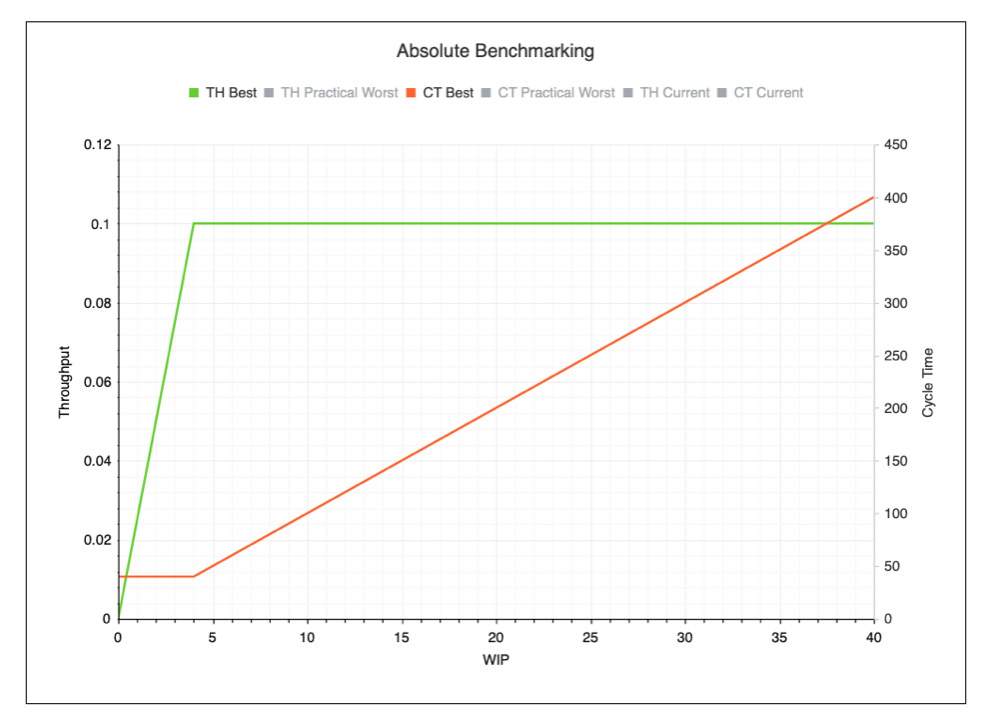 Figure 3: Relationships between TH, CT and Wip plotted.
Figure 3: Relationships between TH, CT and Wip plotted.
As can be seen in Figure 3, TH grows as WIP grows until it reaches an upper limit. This upper limit of the WIP is known as the Critical WIP (CWIP). It is defined as the WIP level that achieves the maximum throughput (bottleneck rate, or BNR) and minimal cycle time (raw process time, or RPT) in a process flow or production system with no variability [1]. For our very simple example, BNR is 0.1 wells per day and RPT is 40 days. Critical WIP can be calculated using Little’s Law:
CWIP = BNR x RPT = 0.1 x 40 = 4.
What is interesting is that TH does not grow beyond BNR, even if WIP increases. Any WIP above the CWIP level does not result in additional throughput, but rather increases CT due to additional wait time; this is obvious from our example production system in Figure 2. As soon as there are four wells being worked on in the production system, any additional wells must wait for permitting, until permitting finishes processing the well, they are currently working on. Any WIP level below CWIP results in lost throughput. Although every production system suffers from variability, CWIP provides a critical benchmark for evaluating current production system performance.
Our example system in Figure 2 is very simple as there is no variability and the numbers have been cooked for ease of illustration. But despite these gross simplifications, it still illustrates some very general principles. The system in Figure 2 is sufficiently generic and the tasks could work equally well for activities in a variety of different projects. For instance, the operations labeled 1 through 4 in Figure 2 could be engineering, fabrication, delivery and site construction, the basic building blocks of a construction project. And while the sample values of throughput and cycle time for the individual steps were artificially kept the same for simplicity of calculation, they need not be. One could generate the equivalents of Table 1 and Figure 3 with a different set of numbers, albeit with a bit more arithmetic. But the system, even one which is more complex than the sequence of the four steps we considered, would exhibit the same general characteristics, meaning there would be a bottleneck rate, there would be a critical WIP level and there would be a raw processing time, all deterministically obtained in the absence of variability.
Even in the absence of variability, this example illustrates some fundamental considerations in production system design and management in projects. Greater WIP than necessary results in more capital tied up without return and a decreased ability to take advantage of technological advancements or regulatory changes. In addition, a recent analysis performed by a company implementing PPM demonstrated that increased WIP beyond the optimal level leads to loss of capacity due to increase in rework and reduction in efficiency.
However, the type of performance illustrated in Figure 3 is unattainable in the real world due to variability in flow, meaning how often and in what chunks (batch size) work is provided to a production unit (a single step or operation in the production system) and variability in process, meaning how long it takes to complete / process a unit of work. Much of the variability that we deal with each day can be categorized by whether it affects the flow or the process.
What is the effect of variability on Figure 3? We’re not ready to be quantitative about that, but we can provide a qualitative discussion, referring to some other examples illustrated in Figure 4 below which show the results of simulating a production system with and without variability.
The relationship between WIP and CT is shown below. When there is no variability (best case performance), CT is equal to Raw Process Time (RPT) until it reaches Critical WIP (CW), and then it increases as WIP increases. When there is variability, CT increases as WIP increases. The maximum TH deteriorates as variability increases. Therefore, as WIP increases, the increase in TH becomes smaller and smaller. However, the detrimental effects of increased WIP can be further understood by examining the relationship between WIP and CT. The graph below depicts the Practical Worst-Case TH and CT for the example above, where Practical Worst Case refers to a state with moderately high variability and a balanced line (i.e., all processes have the same capacity).
 Figure 4: The impact of variability
Figure 4: The impact of variability
Therefore, if you put the relationship between WIP, CT and TH together, it is very easy to see that as WIP increases more and more beyond CWIP, the increase in TH becomes minimal but CT increases tremendously. This can be translated to more capital tied up and delayed delivery of projects. These relationships allow us to clearly understand the need to reduce variability and choose carefully how much WIP to carry in any production system.
Now that we have considered a very simple system, or one in which each process has only one resource and all of the resources have the same capacity, let us now consider a richer case. Consider the situation in Figure 5. Here we continue to have four stages, but each stage has between one to six resources. Moreover, the resource times vary between 10 and 50 days with the first stage, like the previous case, having one resource requiring 10 days, the second having two resources requiring 25 days, the third with 6 resources at 50 days each and the forth having two using 15 days.
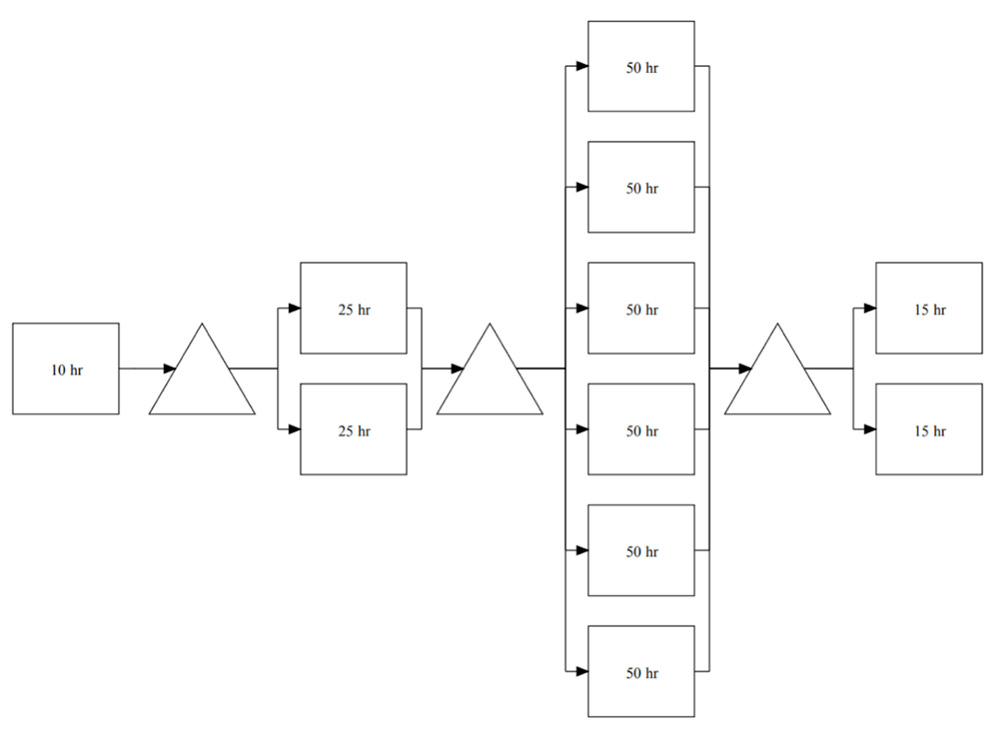 Figure 5: An unbalanced process with parallel stations.
Figure 5: An unbalanced process with parallel stations.
The capacities of the stations are computed by considering the capacity of one station and then multiplying by the number of parallel resources. This yields 1/10 for the first station (as before) and then 2/25, 6/50, and 2/15 for the remaining stations. The minimum is 2/25, or 0.08 units per day, which becomes the bottleneck rate. The raw process time is simply the sum of the process times of all the stations: 100 days. The critical WIP is the product of raw process time and bottleneck rate:
CWIP=RPT×BNR=100×2/25=8
But this time, the critical WIP is not equal to the number of work stations. Why?
If we were to release 8 units into the system and then keep the WIP level at 8 by releasing another unit only when one is completed, we would see some interesting behavior. First, two of the six resources at station 3 would never be used. This is not too surprising because 4/50 = 2/25 and so having only four resources at station 3 would have the same capacity as the bottleneck rate. But what about the others?
Suppose we run the system at its bottleneck rate, which is 0.08 units per day, and calculate the utilization at each station. Utilization is always given by,
u=TH/r
Where TH is the throughput rate and r is the local production rate (or capacity of the station). Since the first station has a rate of 0.1 units per day and the throughput running at the bottleneck rate is 0.08, the utilization of the first station will be 0.8 or 80%. This means that the one resource at station one is busy 80% of the time. So, we need only 0.8 resources (if we could divide them up). The second station is the bottleneck, so we would expect it to be 100% utilized when running at the bottleneck rate (0.08/0.08 = 1 = 100%). Since there are two resources there and we need 100% of the available capacity, we need both of them. Add these to the 0.8 at station 1 and we have 2.8 so far.
Station 3 is more interesting as we have already seen. The potential production out of station 3 is 6/50 = 0.12 units per day. The utilization is (2/25)/ (6/50) = 2/3 or 66.67%. Thus, we need only 2/3 of the available resources and, since there are 6 available, we need only 4. Our total count now becomes 6.8. The last station has a rate of 2/15, so the utilization is (2/25)/ (2/15) = 15/25 = 0.6. And 60% of 2 resources is 1.2. Add these to our count and we get 8, the Critical WIP! These calculations are summarized below in Table 2.
| Station | Number or Resources | Process Time | Station Rate | Utilization and Required No. of Resources |
| 1 | 1 | 10 days | 0.1 units per day | 0.8 | .08 |
| 2 | 2 | 25 days | 0.08 units per day | 1.0 | 2 |
| 3 | 6 | 50 days | 0.12 units per day | 0.667 | 4 |
| 4 | 2 | 15 days | 0.13 units per day | 0.6 | 1.2 |
Table 2: Utilzation of an unbalanced process with parallel stations.
We can conclude that the Critical WIP is equal to the actual number of resources that will be busy under best conditions. By best conditions, we mean maximum throughput and minimum cycle time. But the Critical WIP is also the maximum number of resources that can possibly be busy over the long term for any conditions. Now consider how many resources we had: 1 + 2 + 6 + 2 = 11. Then, the best we can ever hope to do is have 8 out of 11 resources busy, which is 73%. So, the Critical WIP divided by the number of resources indicates the maximum total resource utilization.
What if we are not able to run at 100% utilization of the bottleneck because of variability? The total resource utilization drops even further. If we are running at 90% bottleneck utilization, then we have a 65% total resource utilization.
Now, let’s add variability and compare it to a balanced line with the Practical Worst Case (PWC) having the same BNR and RPT. We have plotted these in Figure 6. Note how the unbalanced case (TH) has greater throughput than the equivalent PWC. Why is this?
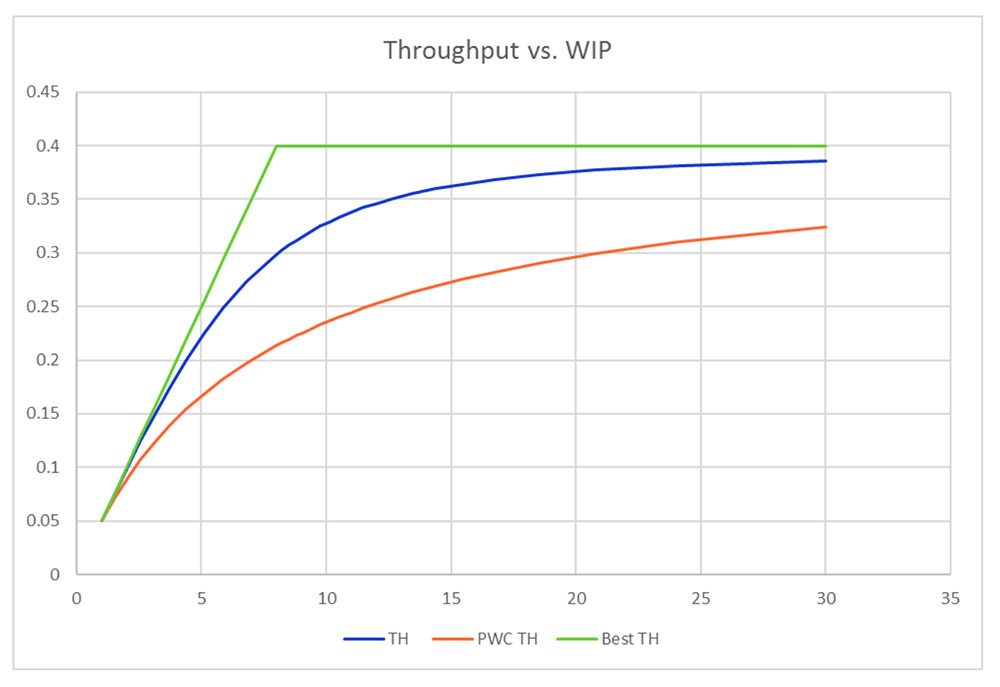 Figure 6: Performance of an unbalanced process with parallel stations and variability.
Figure 6: Performance of an unbalanced process with parallel stations and variability.
It is because the unbalanced case has a significant capacity buffer in the form of extra capacity at the non-bottleneck processes. Remember that only 73% of the resources were ever busy, even under best conditions. This extra capacity helps to increase throughput and reduce cycle time. It does this by forcing any extra WIP (anything above the Critical WIP) to congregate in front of the bottleneck, thereby “protecting” the bottleneck from starvation of work.
The way we control WIP allows this to happen. Recall that we start one unit only when the line finishes a unit. This, in effect, makes the production system more of a production circle than a production line. It is as though the unit that finished moved to the front of the line to go through again. In other words, it behaves like there is no beginning or end of the line. Thus, any extra WIP in the line will naturally move to the slowest process—the bottleneck.
Now think about the third stage, the one with 6 stations that only utilized 4 on average. What would happen to the curve of the system if we were to reduce the number of stations from 6 to 4? The curve would move down, meaning less throughput for the same WIP, because we have a smaller capacity buffer. The question is whether it is worth it to add this capacity, and should we add one or two.
.
 Figure 7: Throughput with various amounts of extra capacity.
Figure 7: Throughput with various amounts of extra capacity.
In Figure 7 we see what happens if we have 4, 5, and 6 resources at the third station. Adding one results in a fairly significant increase but adding yet another one results in almost no increase. This provides a valuable lesson: extra capacity offers diminishing returns. A little extra is good, but a lot is not much better.
We have seen how increasing WIP will increase throughput but only so far. At low WIP levels (below the Critical WIP), increasing WIP greatly increases throughput while cycle times are changed little. But at high WIP levels, the reverse is true: cycle times increase linearly with increasing WIP while throughput is almost not affected. What we did not see in our simple model, is how throughput can decrease with excessive WIP. We will explore this effect in another article in this series.
When we looked at the effects of variability on throughput and cycle time, we discovered that even with the same bottleneck rate and raw process time, additional variability always increases cycle times and decreases throughput, with both being detrimental to system performance.
Finally, we demonstrated how having additional capacity can mitigate the effects of variability. Extra capacity, even at non-bottlenecks, will increase throughput and decrease cycle time. But when adding extra capacity, a little goes a long way. Of course, if we had increased the capacity at the bottleneck, the effect would be much greater since we would change the bottleneck rate thereby changing the entire performance curve.
We will take a closer look at the quantitative impact of variability on cycle time, throughput and utilization in the next tutorial article in this series.

